
📚 Understanding Whats Behind AI Chatbot
Part of a 4-post series
All posts in this series:
- 1.What is a Large Language Model (LLM)?
- 2.What is prompt engineering?
- 3.What is RAG? (Current)
- 4.Designing an AI Chatbot
In our previous articles, we explored how LLMs are trained on vast datasets and how transformer architecture helps them predict the next word (token). We then learned about prompt engineering and discovered how the input we provide significantly influences an LLM's output quality.
But here's a critical limitation: What happens when we need an LLM to respond about information it wasn't trained on?
Imagine asking ChatGPT about:
- Your company's internal policies
- Recent news events after its training cutoff
- Personal documents or proprietary data
- Real-time information like stock prices
In such cases, the LLM might generate responses that are inaccurate, fabricated, or completely made up. This phenomenon is known as hallucination—when AI confidently provides incorrect information.
The Solution: Retrieval-Augmented Generation (RAG)
To address this limitation and enhance the accuracy of LLM responses, we can use a technique called Retrieval-Augmented Generation (RAG). RAG combines the strengths of information retrieval systems with generative models to provide more reliable and contextually relevant answers.
Think of RAG as giving an AI assistant access to a constantly updated library of information, rather than relying solely on its training memory.
How RAG Works: The Five-Step Process
1. Embeddings: Converting Text to Numbers
The process begins by converting textual data into numerical representations called embeddings. These aren't just random numbers—they capture the semantic meaning of words, phrases, or entire documents in high-dimensional space.
Example: The words "car" and "automobile" would have very similar embeddings, even though they're spelled differently, because they have similar meanings.
2. Vector Database: Storing Knowledge Efficiently
These embeddings are stored in a vector database—a specialized database designed to handle high-dimensional data efficiently. Popular options include Pinecone, Weaviate, and Chroma.
Why vectors? They enable lightning-fast similarity searches. Instead of searching through text word-by-word, the system can find semantically similar content in milliseconds.
3. Retrieval: Finding Relevant Information
When you ask a question, RAG first converts your query into an embedding, then searches the vector database for the most similar embeddings. This retrieval step ensures the model has access to up-to-date and accurate information.
Example: Query "How do I reset my password?" → Retrieves company documentation about password reset procedures.
4. Augmentation: Enriching the Context
The retrieved information is then used to augment your original prompt, providing the LLM with additional context. This is like giving the AI relevant reference materials before asking it to answer.
5. Generation: Creating Informed Responses
Finally, the LLM generates a response based on the augmented input. By incorporating relevant retrieved data, the LLM produces outputs that are more reliable and less prone to hallucinations.
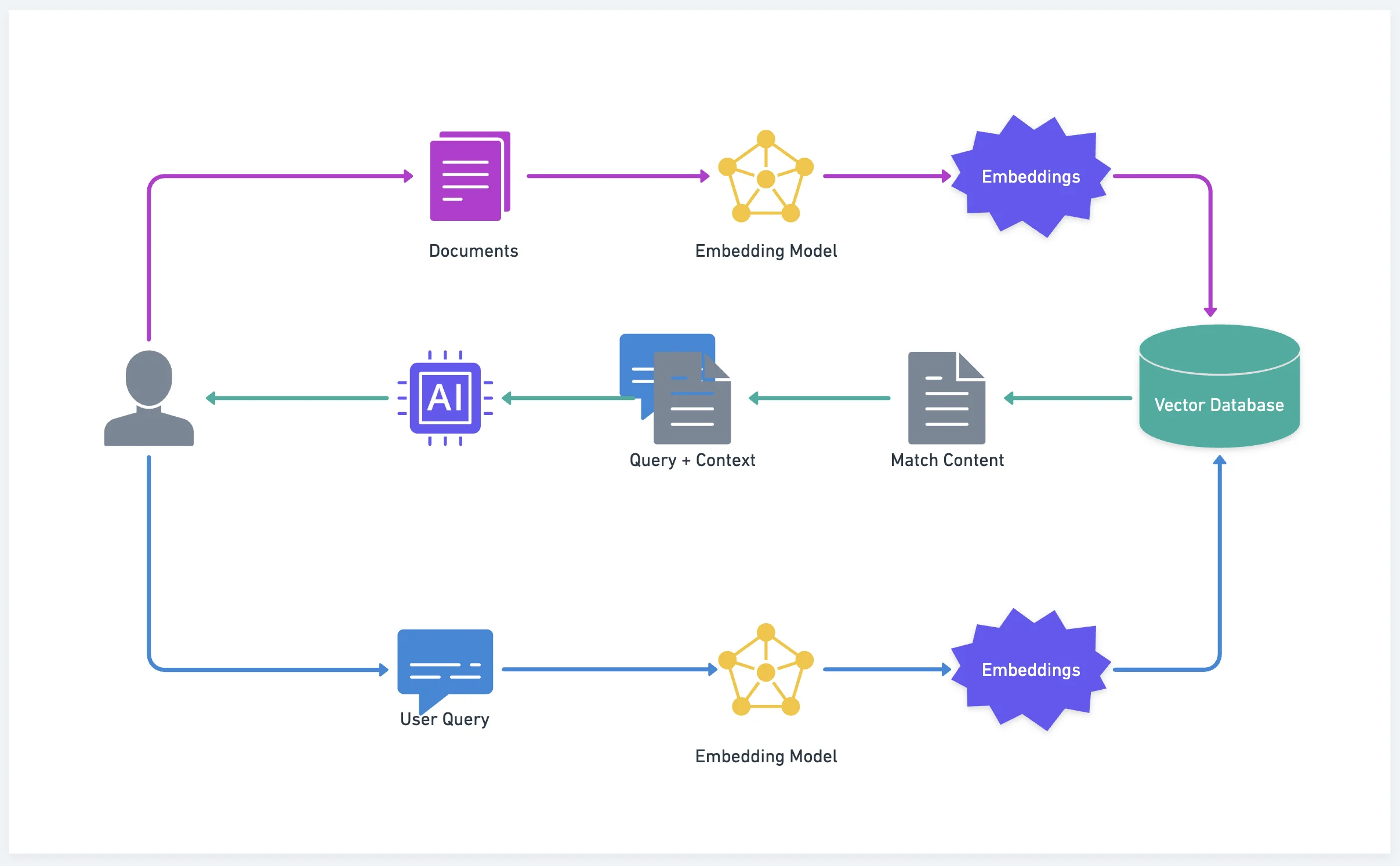 RAG architecture diagram
RAG architecture diagram
RAG in Action: A Legal Research Example
Let's see how RAG transforms AI assistance with a concrete example:
Scenario: A legal research assistant helping a lawyer prepare for a case
Lawyer's Question: "What's the current precedent for fair use in copyright cases involving AI-generated art?"
Without RAG ❌
The system generates a response based only on its training data, which might:
- Not include recent court decisions
- Misinterpret complex legal nuances
- Provide outdated or generic information
- Risk hallucinating fake case citations
With RAG ✅
Step 1: Retrieval
- Searches through legal databases, recent court decisions, and law journals
- Retrieves relevant cases like recent rulings on AI art copyright issues
- Finds specific language from judges' opinions on fair use doctrine
Step 2: Generation The system generates a response that:
- Summarizes retrieved case law and legal principles
- Organizes information by jurisdiction and relevance
- Cites specific cases and statutes the lawyer can reference
- Identifies potential arguments based on legal precedents
Result: The lawyer receives accurate, current information based on the most recent legal authorities, not outdated training data.
When to Use RAG: Key Applications
RAG is particularly effective for:
🏢 Enterprise Knowledge Management
- Internal policies and procedures
- Product documentation
- Employee handbooks
- Technical specifications
⚖️ Domain Expertise
- Legal research and case law
- Medical literature and guidelines
- Financial regulations and compliance
- Academic research papers
📊 Real-Time Information
- Current market data and stock prices
- News and recent events
- Live inventory and product availability
- Dynamic pricing information
🔒 Sensitive Data Handling
- Keeps proprietary information in controlled databases
- Maintains data security and access controls
- Avoids embedding sensitive data in model parameters
- Enables audit trails and compliance monitoring
The Power of External Memory
At its core, RAG extends LLM capabilities by providing external, updatable memory that complements the model's inherent language understanding abilities. It's like giving an AI assistant access to a constantly updated, searchable library of information.
This is part of our series "Understanding What's Behind AI Chatbot." Check out our previous articles on Large Language Models and Prompt Engineering to build your AI knowledge foundation.